Recently I have been busy juggling with big data. It is such a deep ocean with wide range of domain knowledge and was particularly difficult for someone who does not have a comsci background. Although there are a lots of resource floating around the internet but not all of them are intuitive. After all the filtering and trial and error I have done through the journey of learning big data ecosystem, thought I should write a comprehensive tutorial not only as a way for my own documentation, but also for people who are in the same boat I was because I never found one single learning resource where it explains things in detailed from the ground up and from scratch! .Hope the stuff I share here would be of use for someone starting the big data journey, as the tech world is moving fast for sure. I remember when I finished my undergraduate degree, we were using SPSS as a “database” and things certainly have changed drastically with new technalogy. Not sure what the future looks like but it is very exciting and scary at the same time.
Some may argue as a statistician or data scientist, one does not need to learn the engineering side of things. Indeed, of course in the real world these tasks will be divided amongst, software engineer, system architect , system admin, ML engineer, data engineer, ETL people, database administrator ,data scientist. However, learning some or even all of them will give you a cohesive view of the entire eco system: e.g. from a single meta data to a fully deployed ML solution. Which might come in handy sooner or later.
Let’s dive in! (Github repository to my work can be found here)
(more…)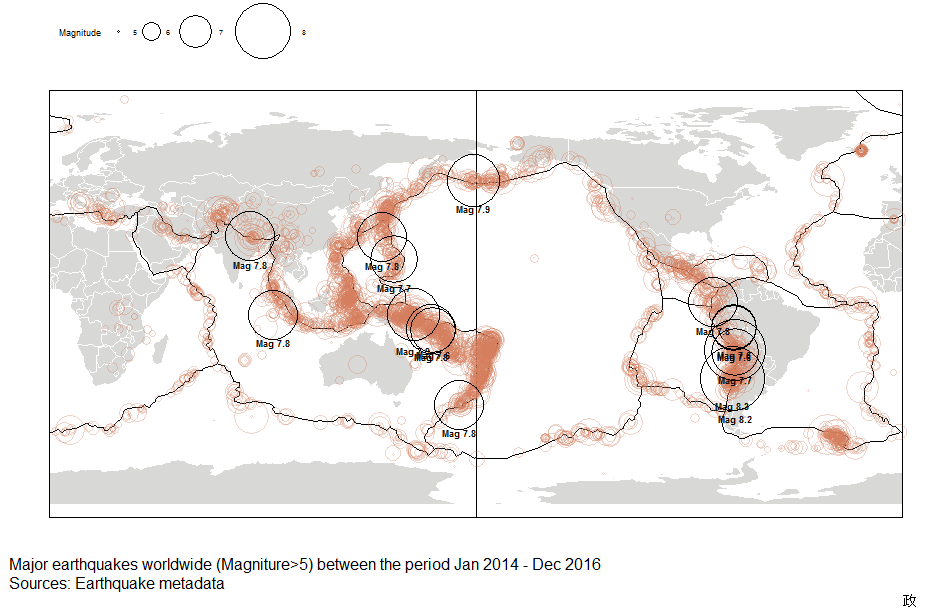
{kind=link}
{kind=link}
{kind=link}