Recently I have been busy juggling with big data. It is such a deep ocean with wide range of domain knowledge and was particularly difficult for someone who does not have a comsci background. Although there are a lots of resource floating around the internet but not all of them are intuitive. After all the filtering and trial and error I have done through the journey of learning big data ecosystem, thought I should write a comprehensive tutorial not only as a way for my own documentation, but also for people who are in the same boat I was because I never found one single learning resource where it explains things in detailed from the ground up and from scratch! .Hope the stuff I share here would be of use for someone starting the big data journey, as the tech world is moving fast for sure. I remember when I finished my undergraduate degree, we were using SPSS as a “database” and things certainly have changed drastically with new technalogy. Not sure what the future looks like but it is very exciting and scary at the same time.
Some may argue as a statistician or data scientist, one does not need to learn the engineering side of things. Indeed, of course in the real world these tasks will be divided amongst, software engineer, system architect , system admin, ML engineer, data engineer, ETL people, database administrator ,data scientist. However, learning some or even all of them will give you a cohesive view of the entire eco system: e.g. from a single meta data to a fully deployed ML solution. Which might come in handy sooner or later.
Let’s dive in! (Github repository to my work can be found here)
We will start with a Env setup first. Here I assumed you already have some working knowledge with a cluster machine, or VM machines.
1. adding public key to your cloud (e.g.
| Username | Key |
| ----------- | ----------- |
| root | ssh-rsa AAAAB3Nz |2. make sure your can passwordless ssh between instances within the cluster
edit sshd_config and set PasswordAuthentication=yes and PermitRootLogin=yes
3. Let’s give root a password
sudo -i
sudo passwd4. Restart SSH service
service ssh restart5. Move public keys to workers in the cluster
cd ~
ssh-keygen -t rsa -N "" -f .ssh/id_rsa
chmod 600 .ssh/id_rsa
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa root@cluster-d836-w-0 "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa root@cluster-d836-w-1 "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa [email protected] "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa [email protected] "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa [email protected] "cat >> ~/.ssh/authorized_keys"
cat ~/.ssh/id_rsa.pub | ssh -i ~/.ssh/id_rsa [email protected] "cat >> ~/.ssh/authorized_keys"
when id_rsa was cat from master to worker server, permission changed. You may encounter below error and you may change the linux permission according to your requirement
<!--
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0745 for '/root/.ssh/id_rsa' are too open.
It is required that your private key files are NOT accessible by others.
This private key will be ignored.
Load key "/root/.ssh/id_rsa": bad permissions
root@cluster-798b-m's password:
--->
6. Check passwordless ssh between instances is working
ssh [email protected]
ssh root@cluster-d836-w-0
ssh root@cluster-d836-w-1
ssh root@cluster-d836-m7. Few other things to remember
- Whitelisting IPs for accessing your cluster
- Disable/Config firewall or ip tables for common ports that will be used by the big data services
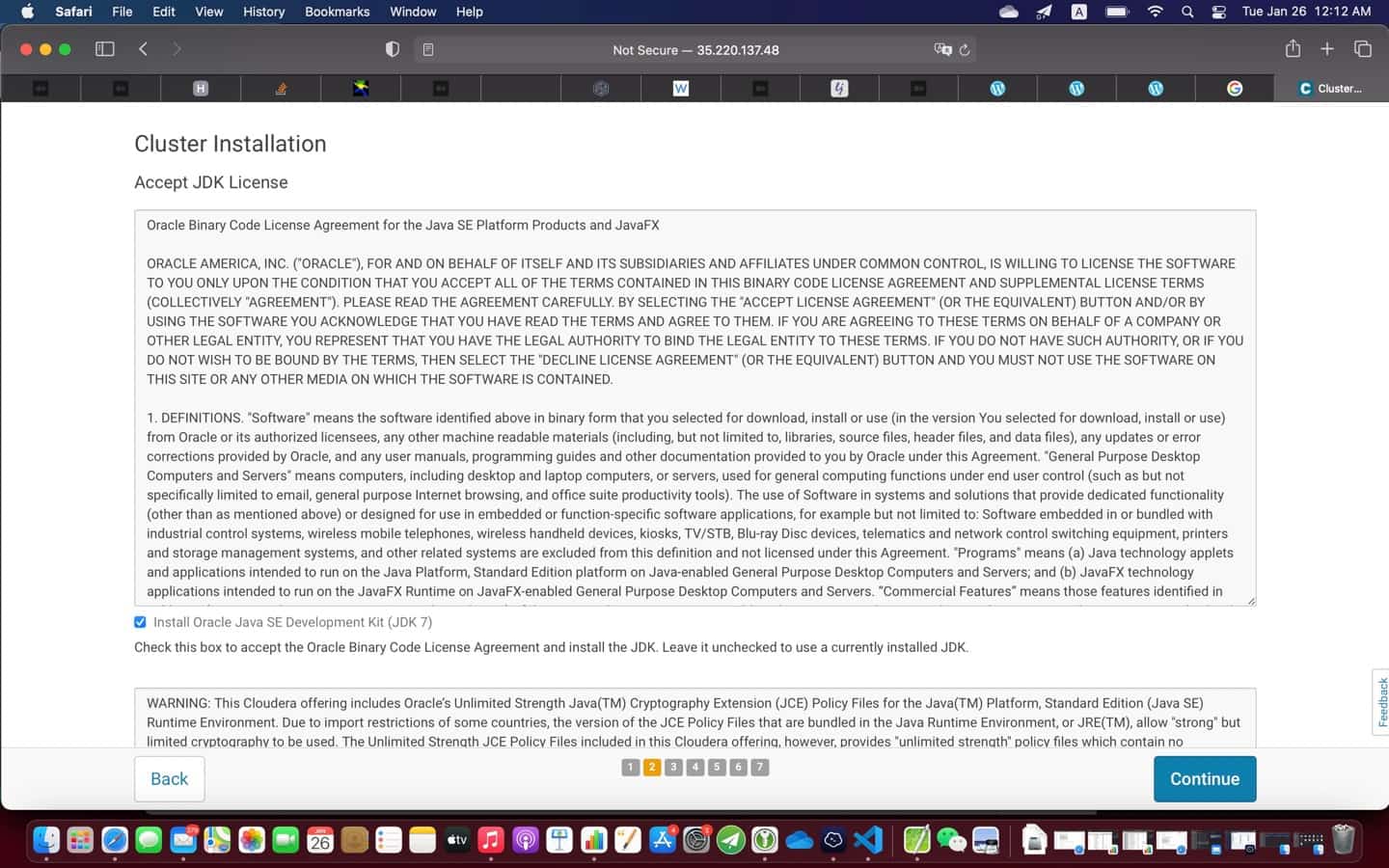
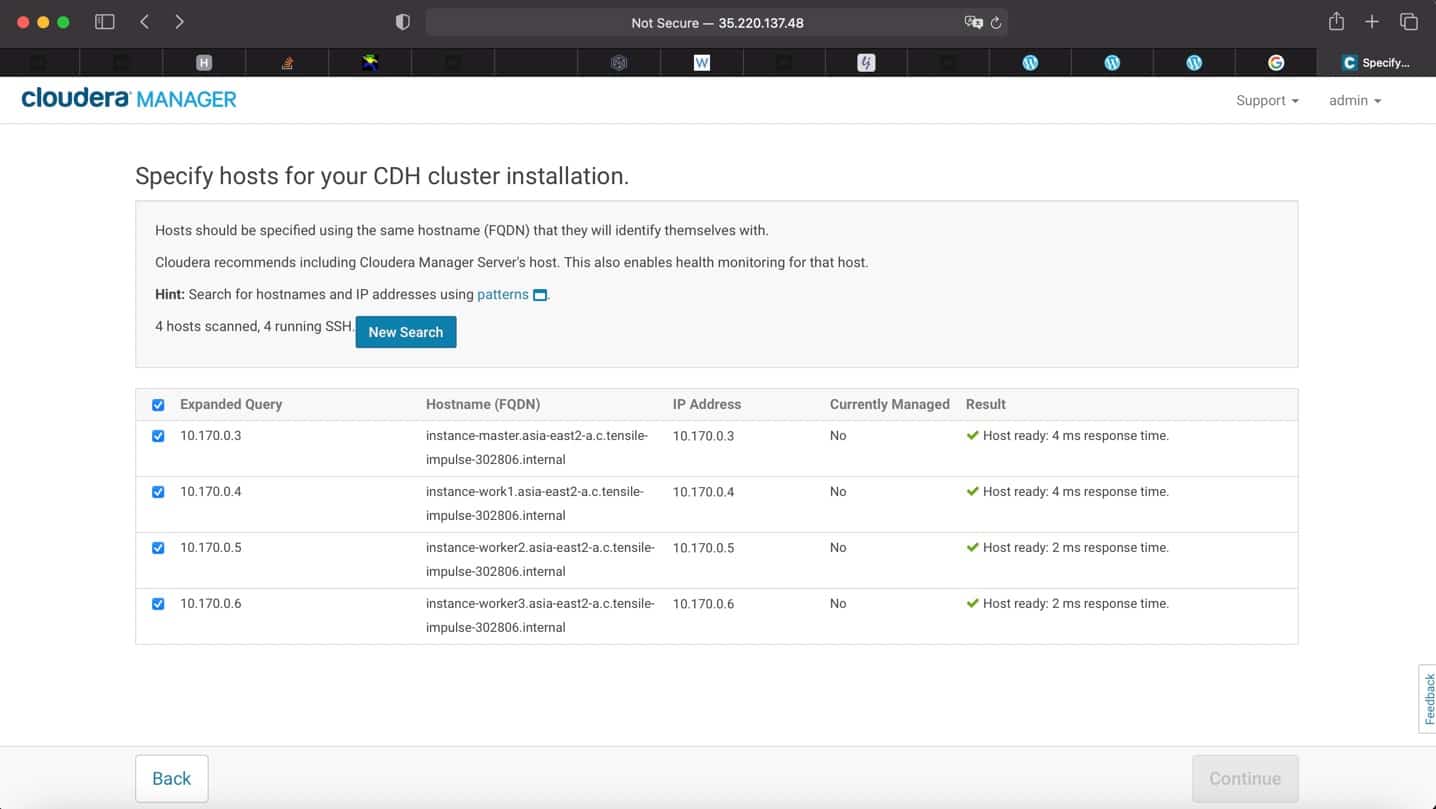
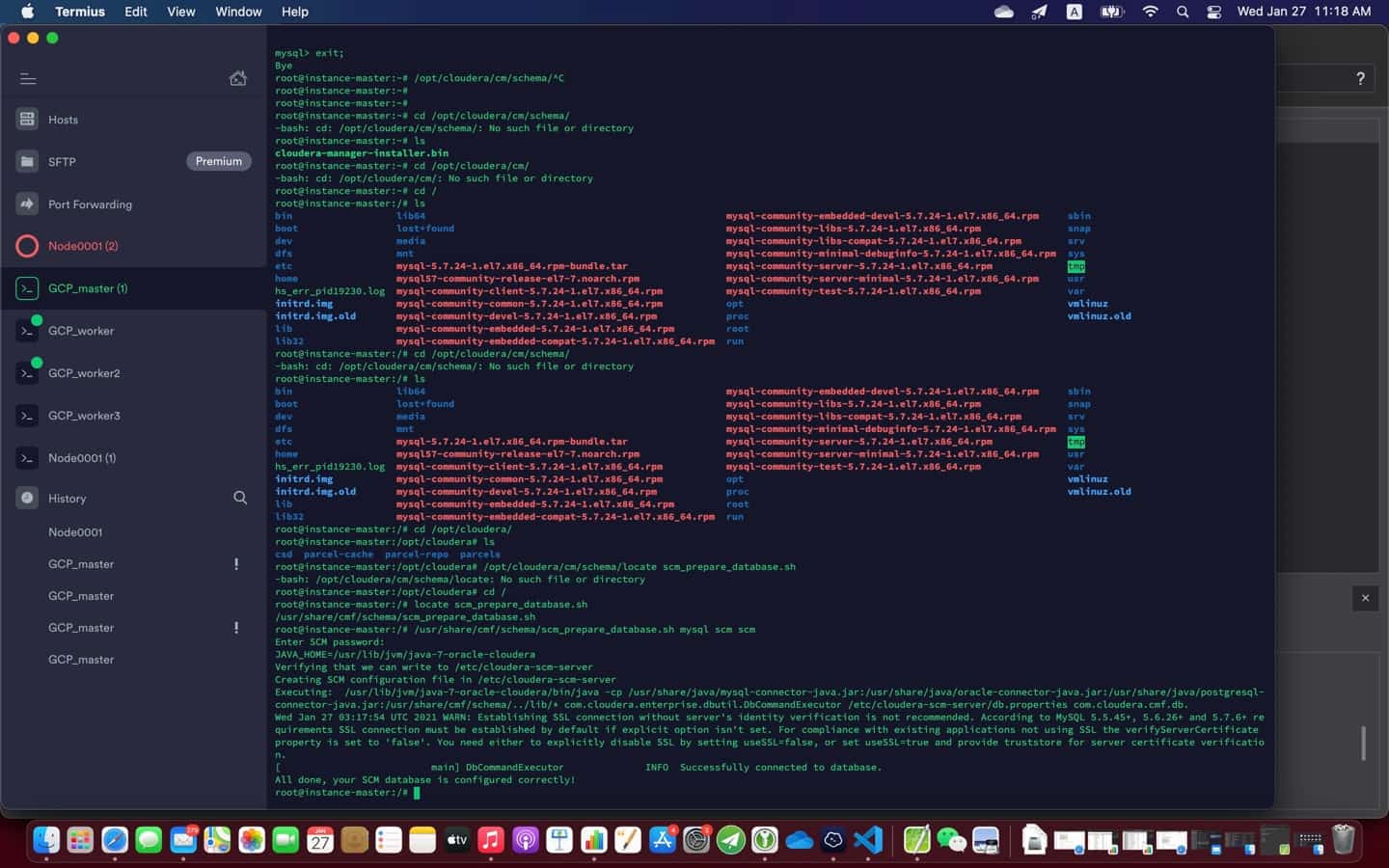
8. You are all set! You can now start CDH installation
$ chmod u+x cloudera-manager-installer.bin
$ sudo ./cloudera-manager-installer.bin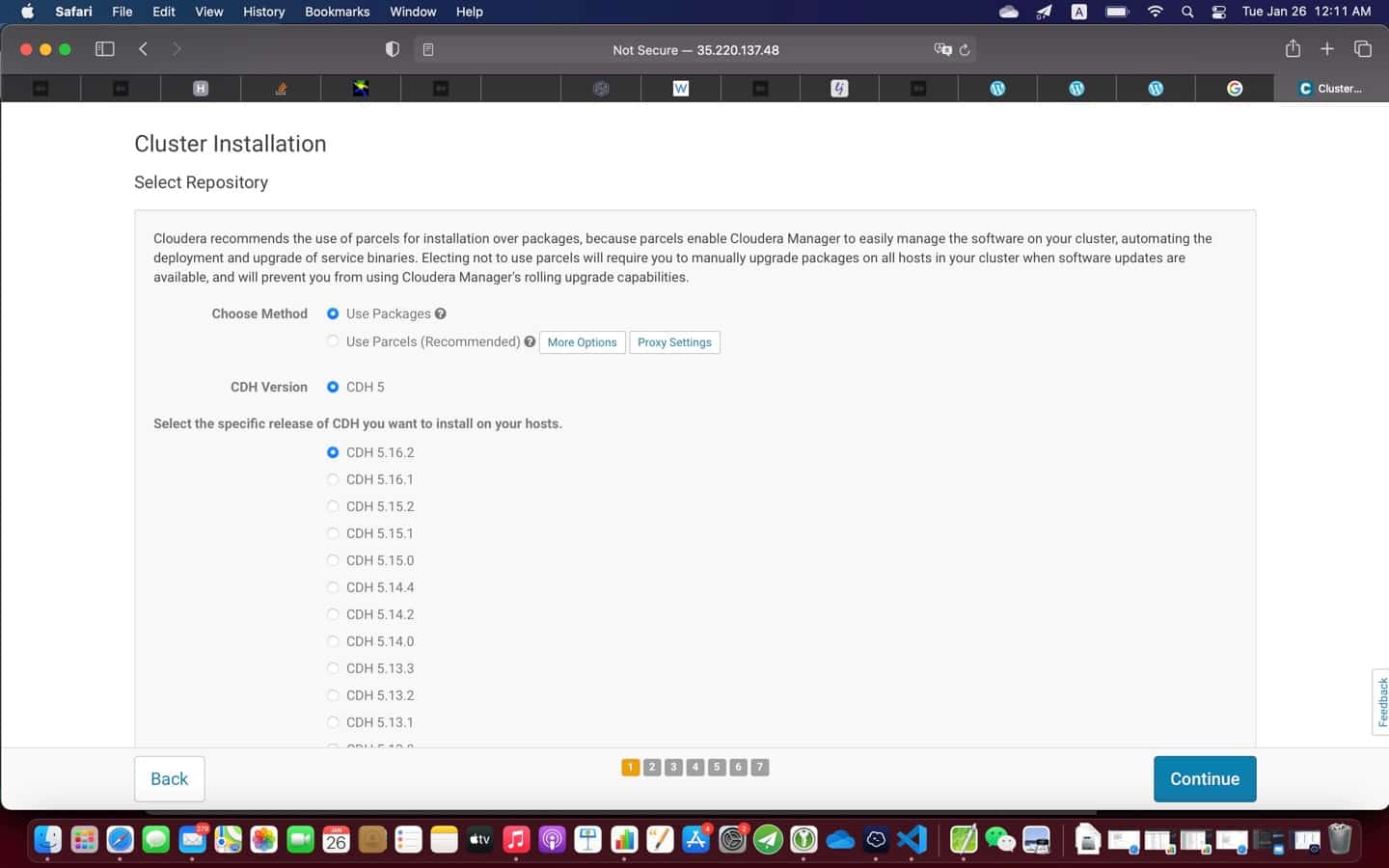
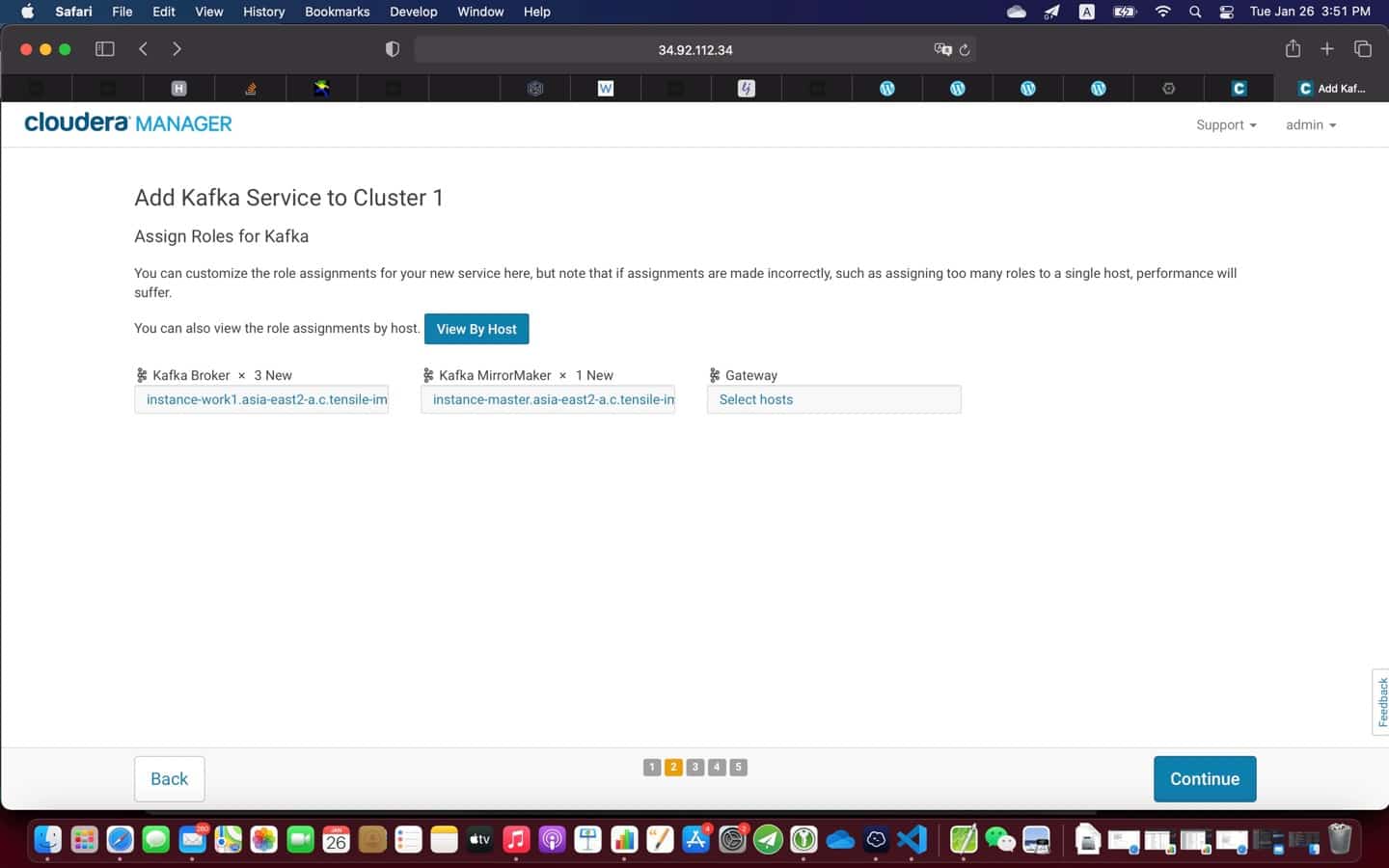
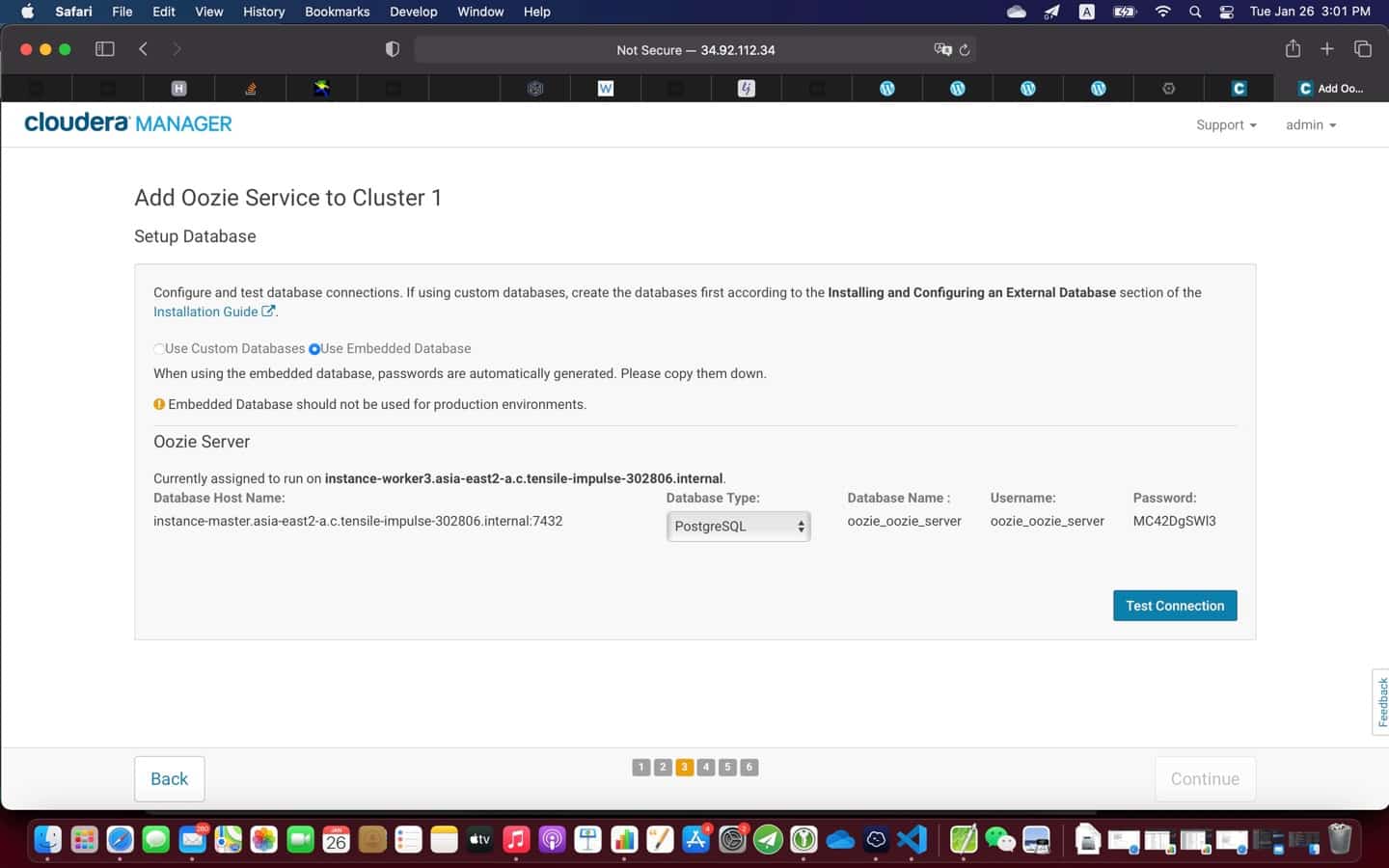
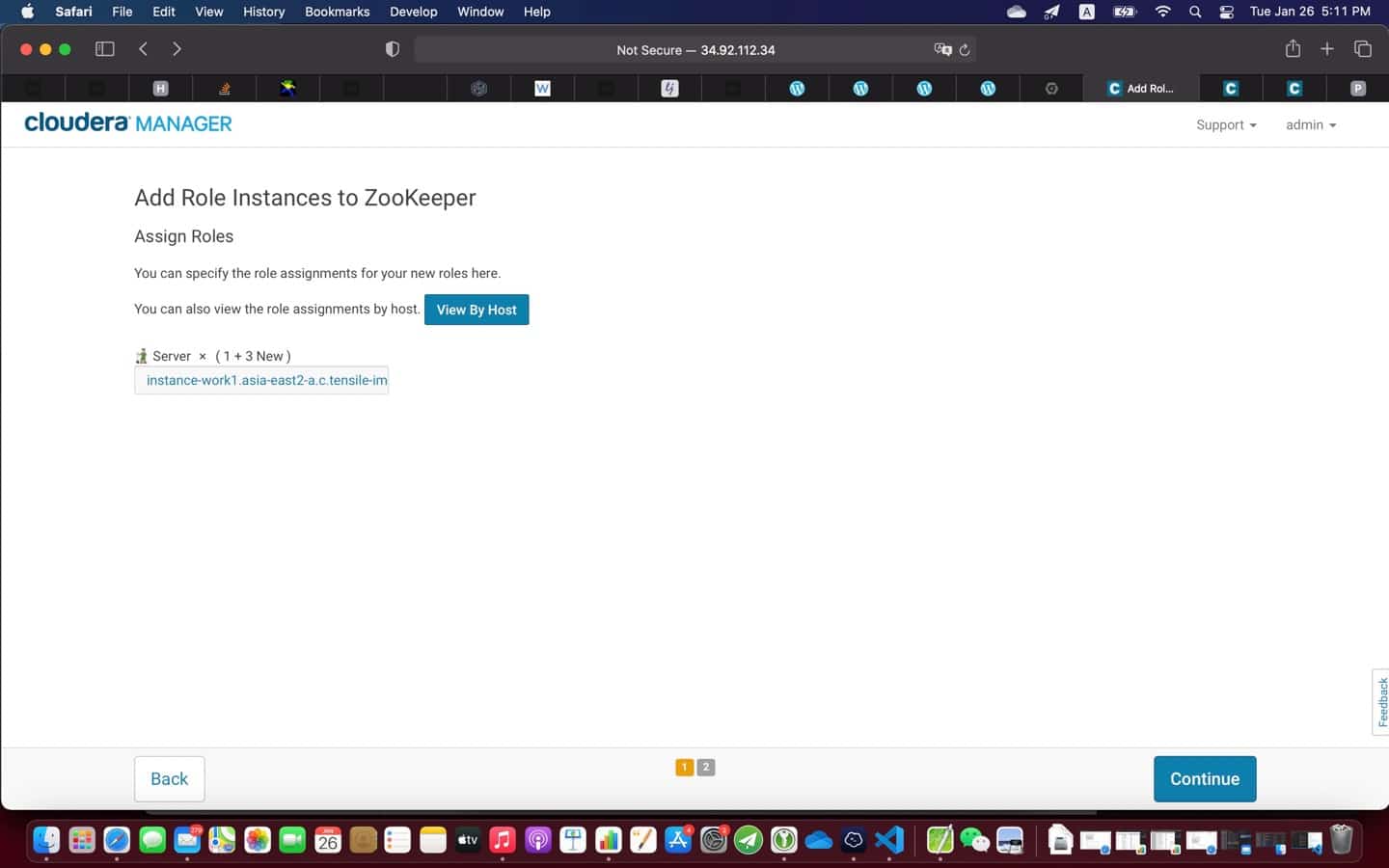
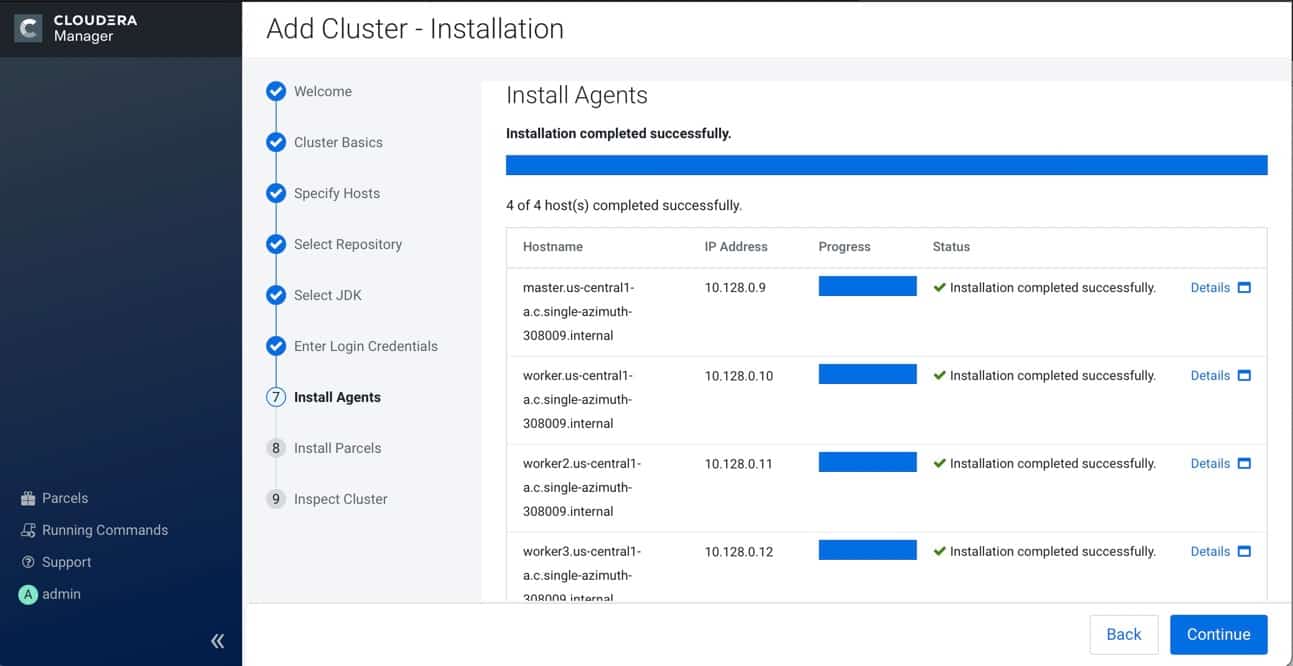


{kind=link}
{kind=link}
{kind=link}
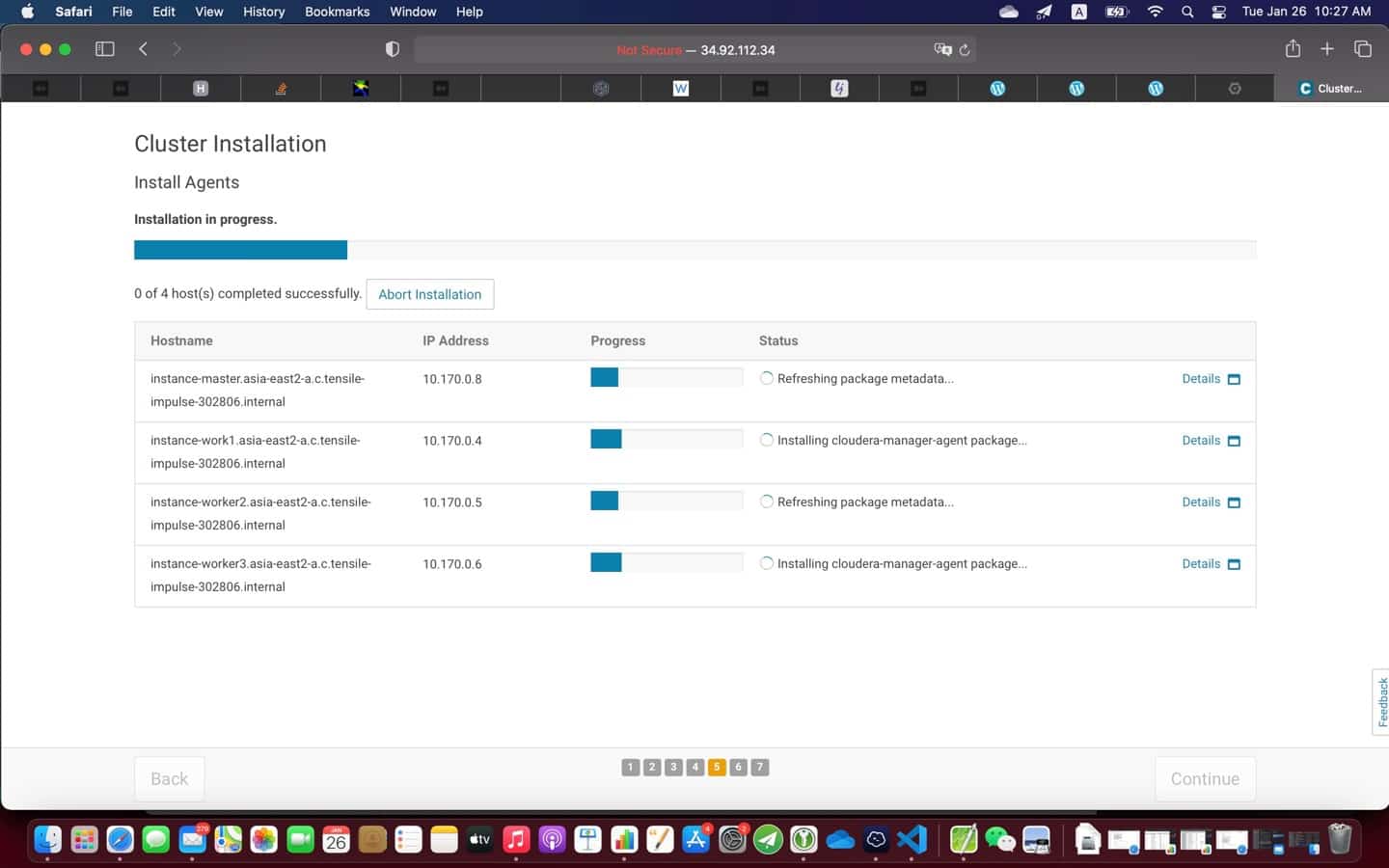
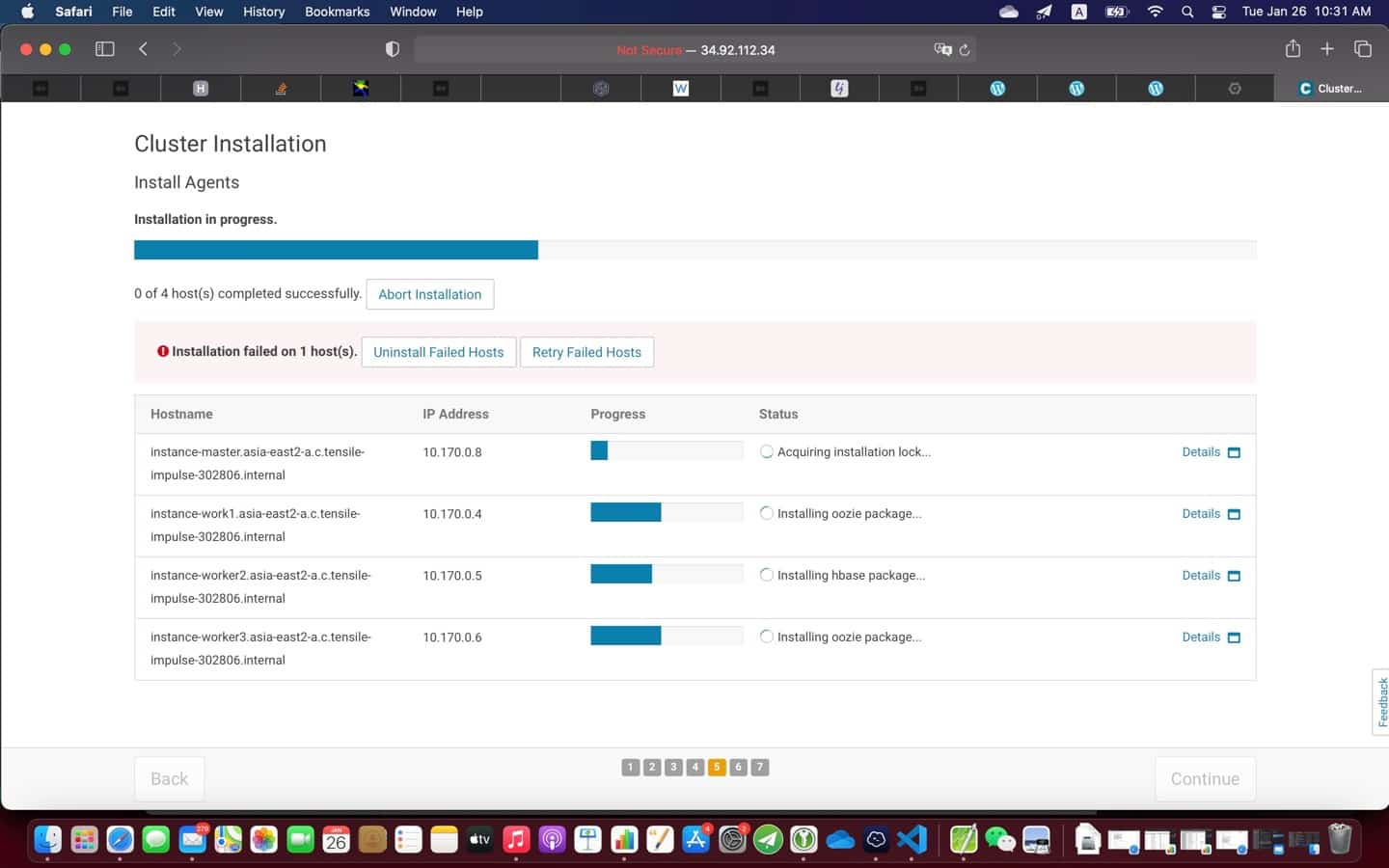
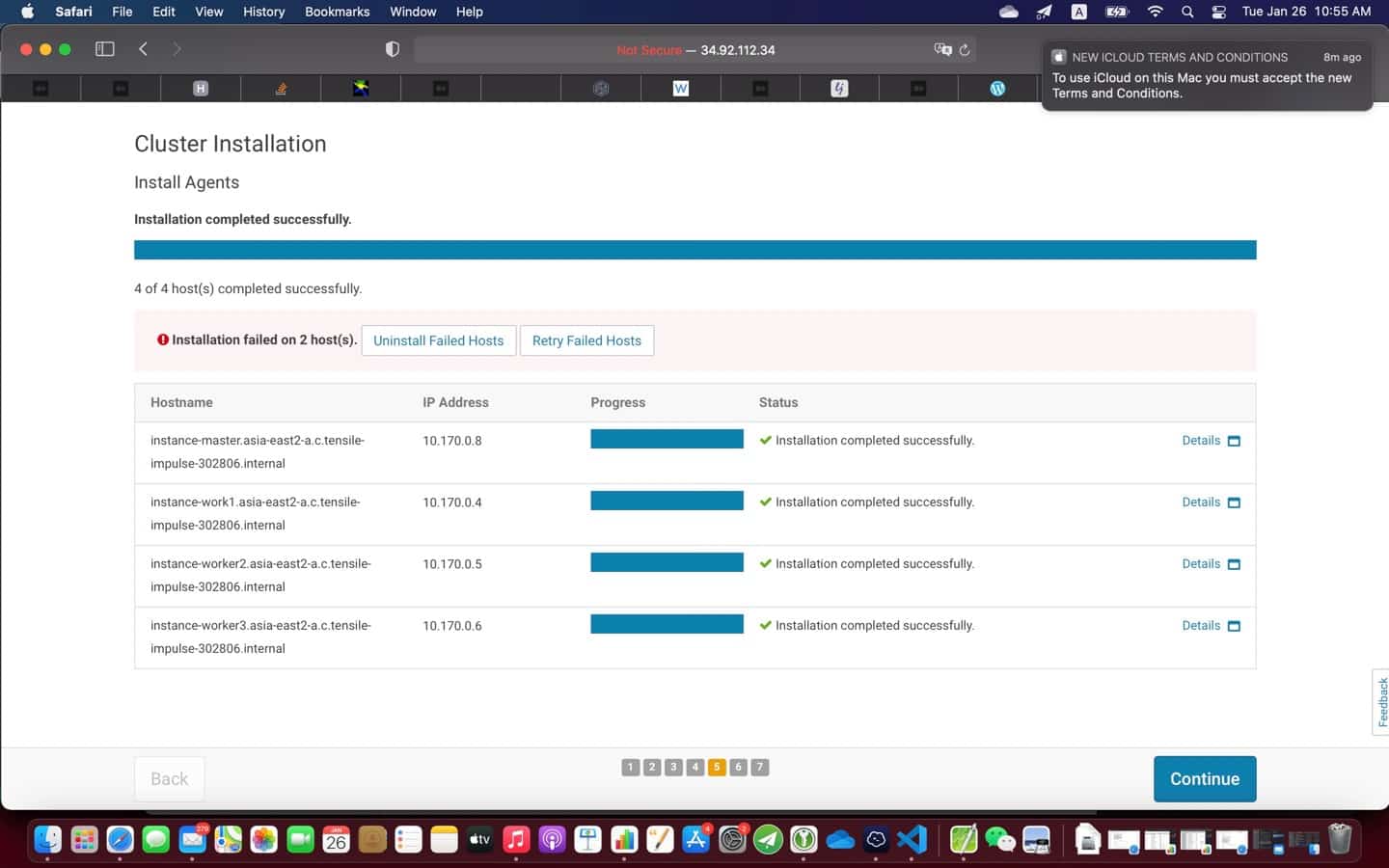
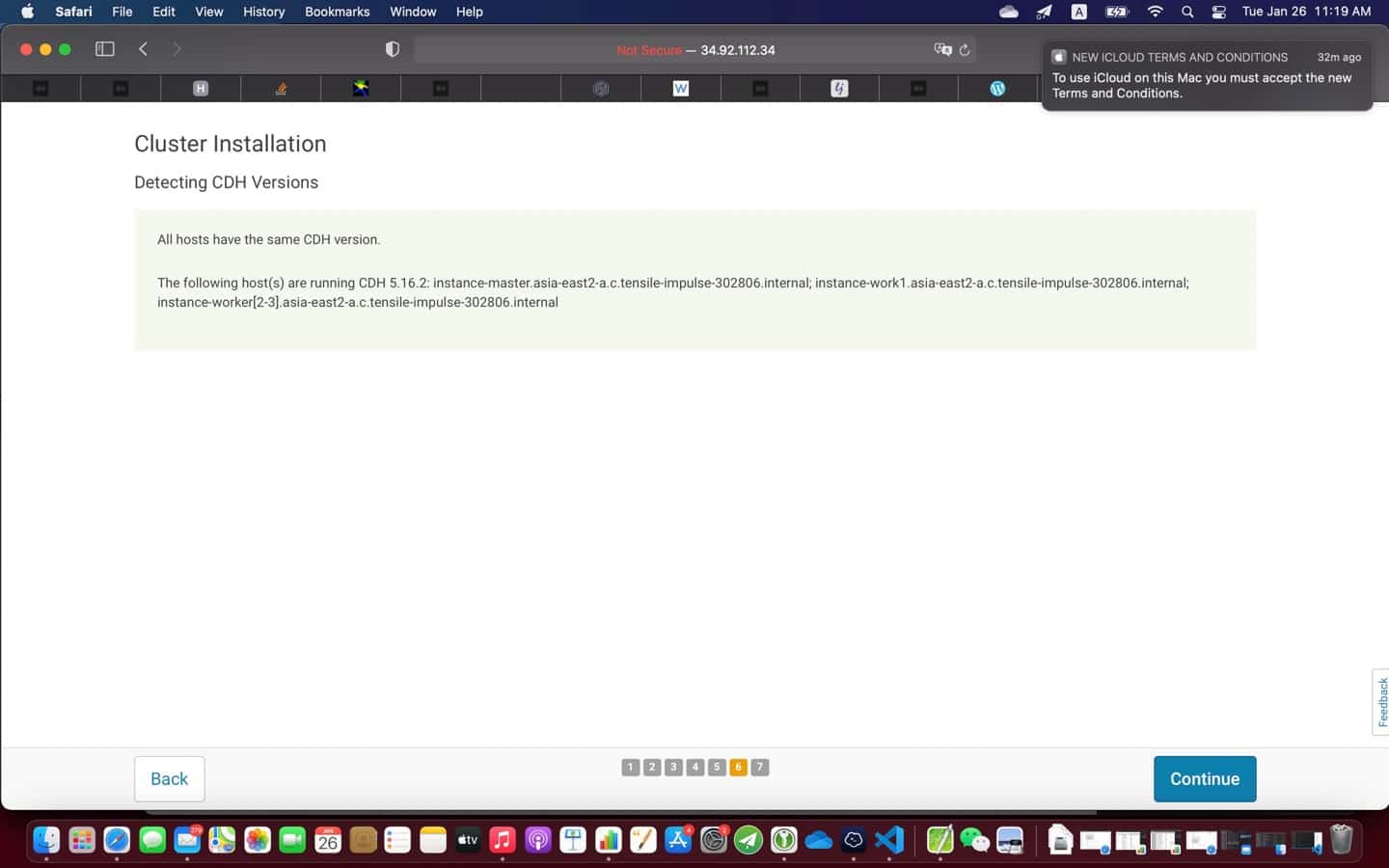
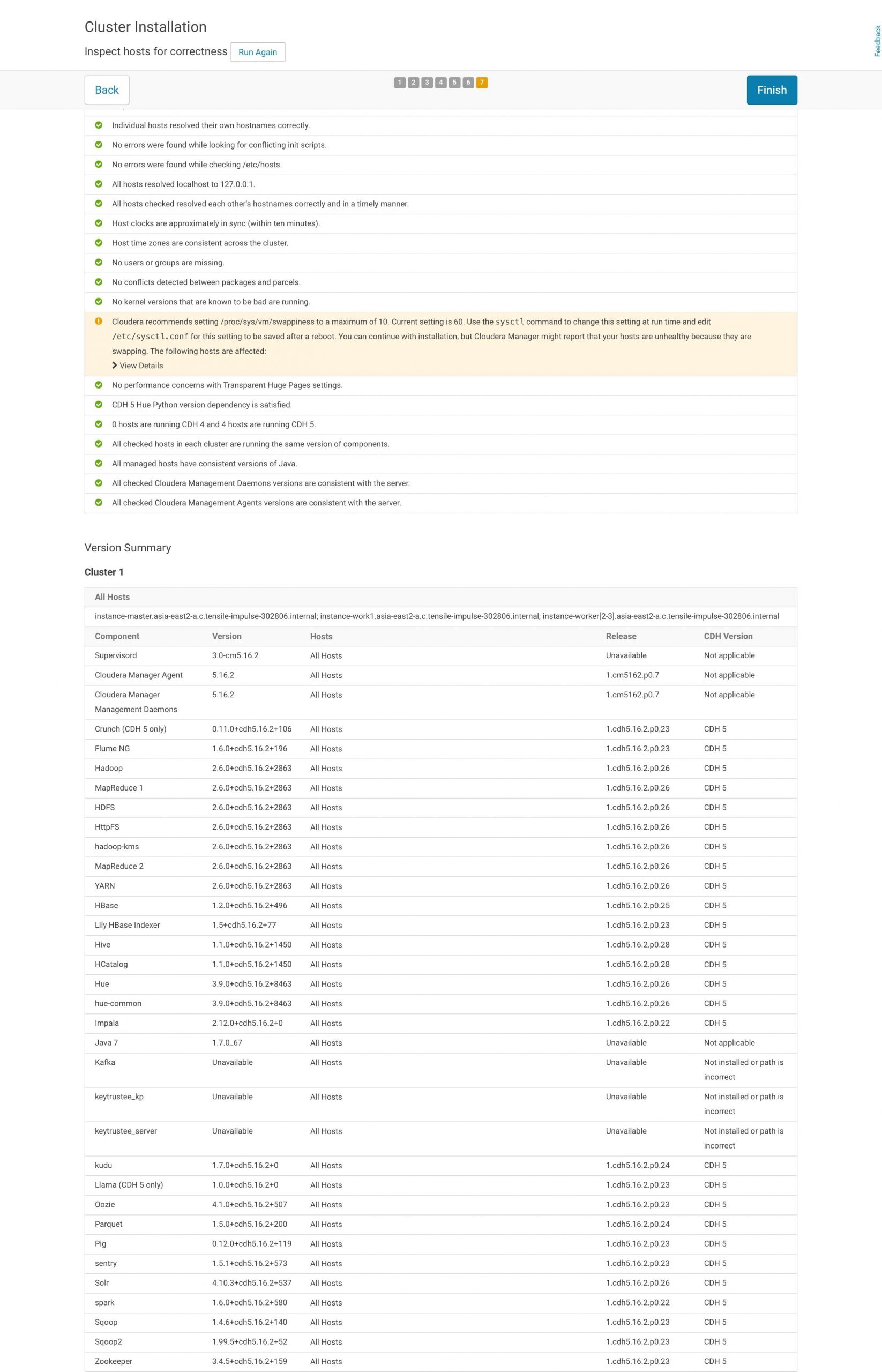
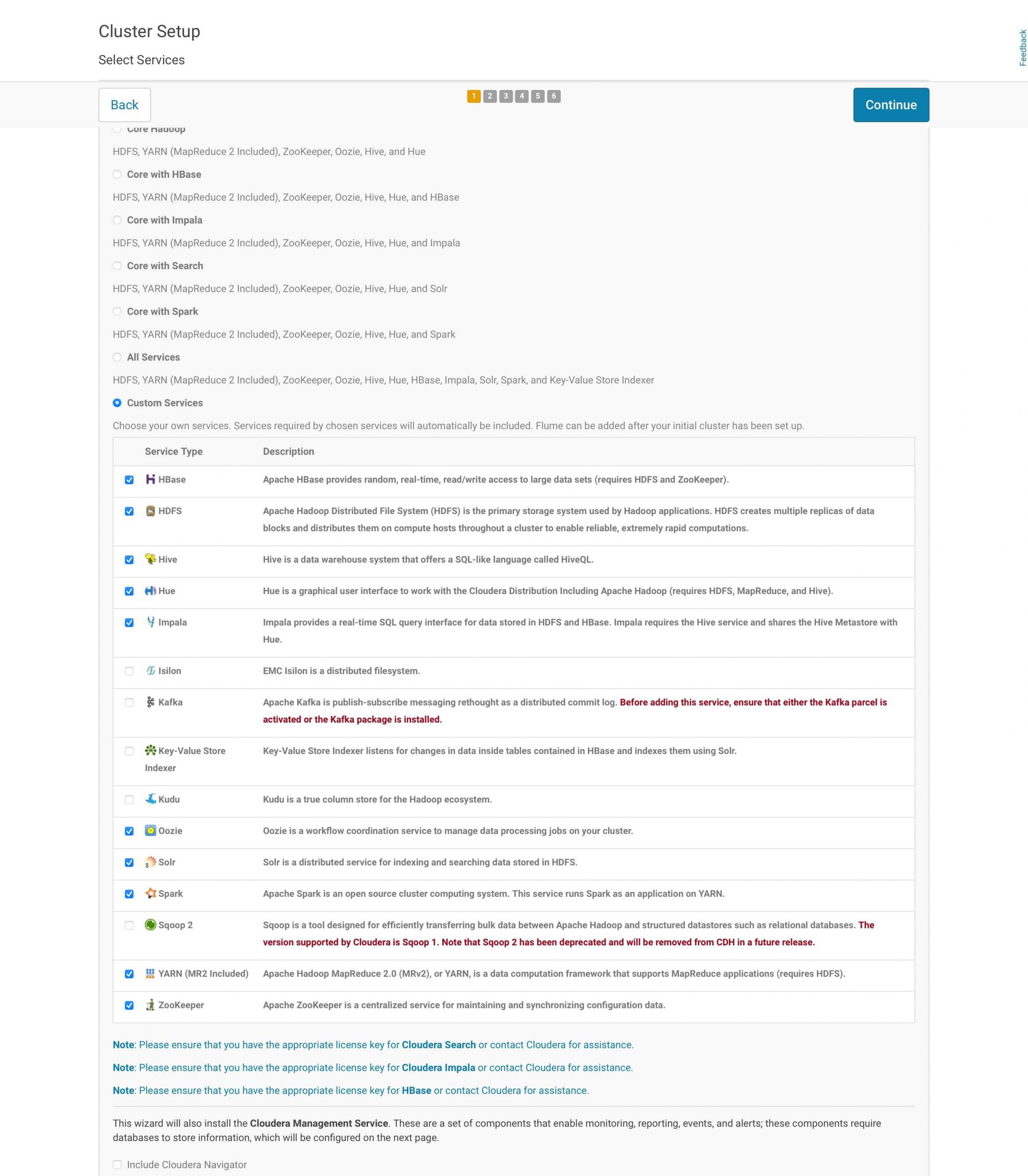
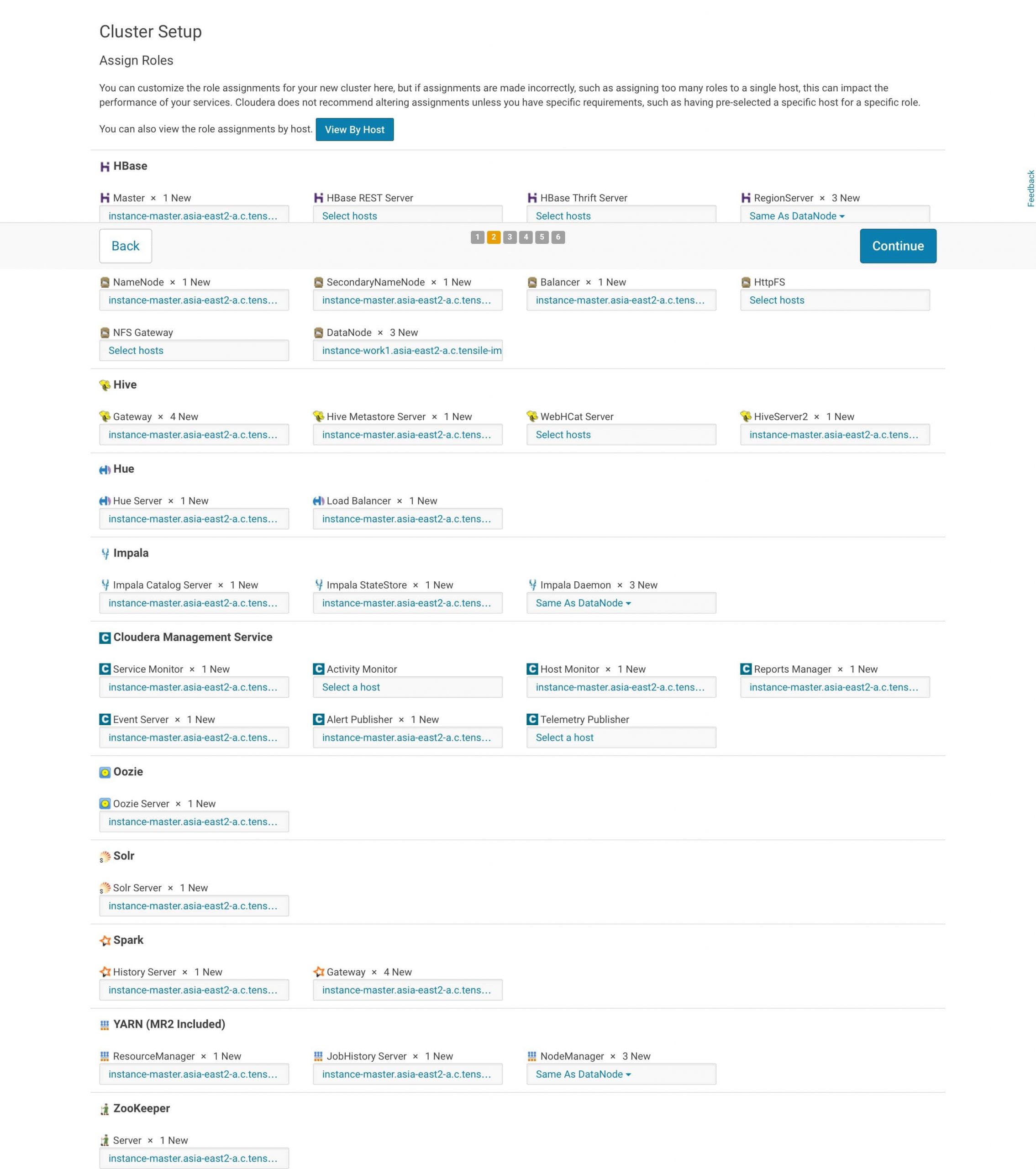
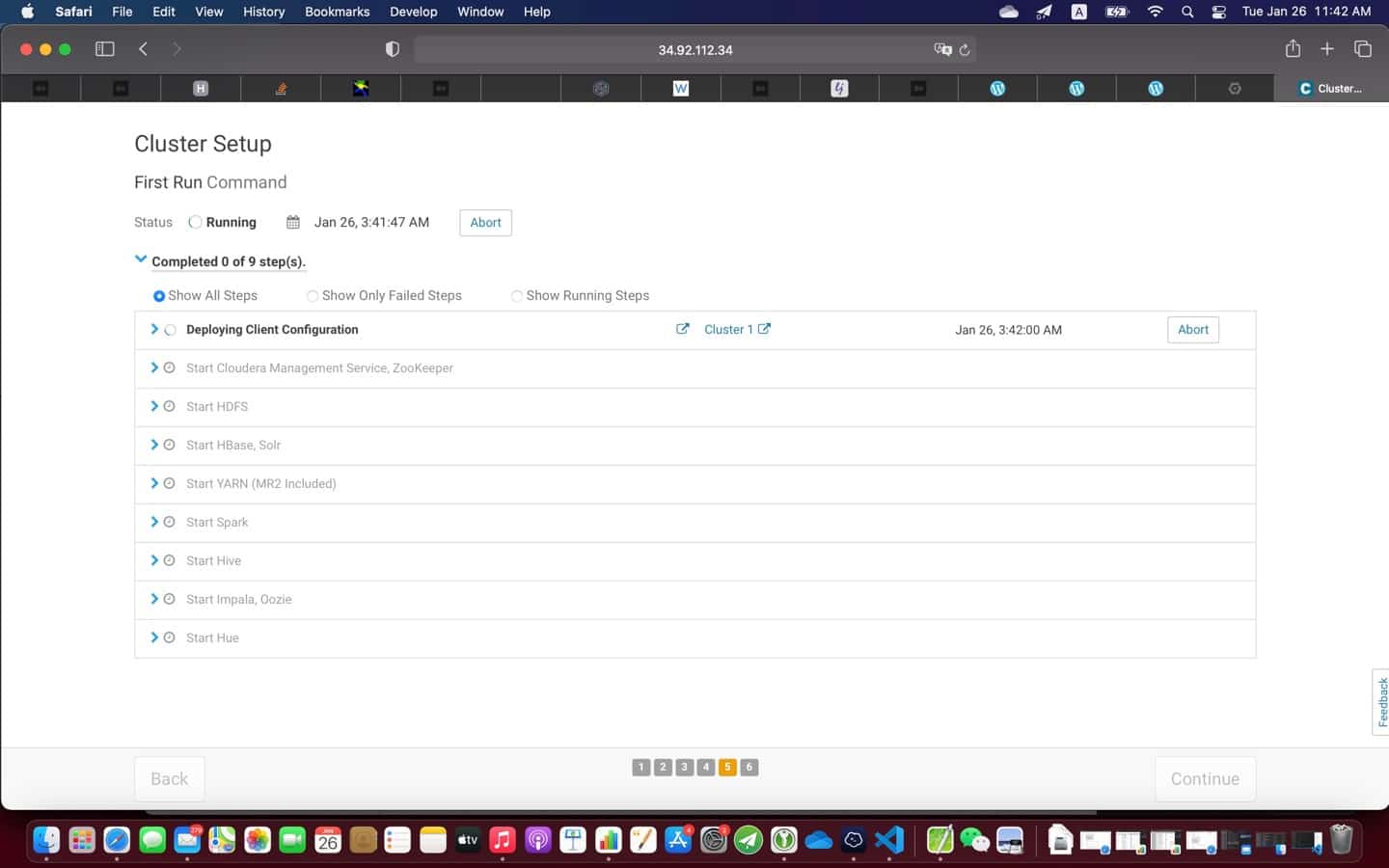
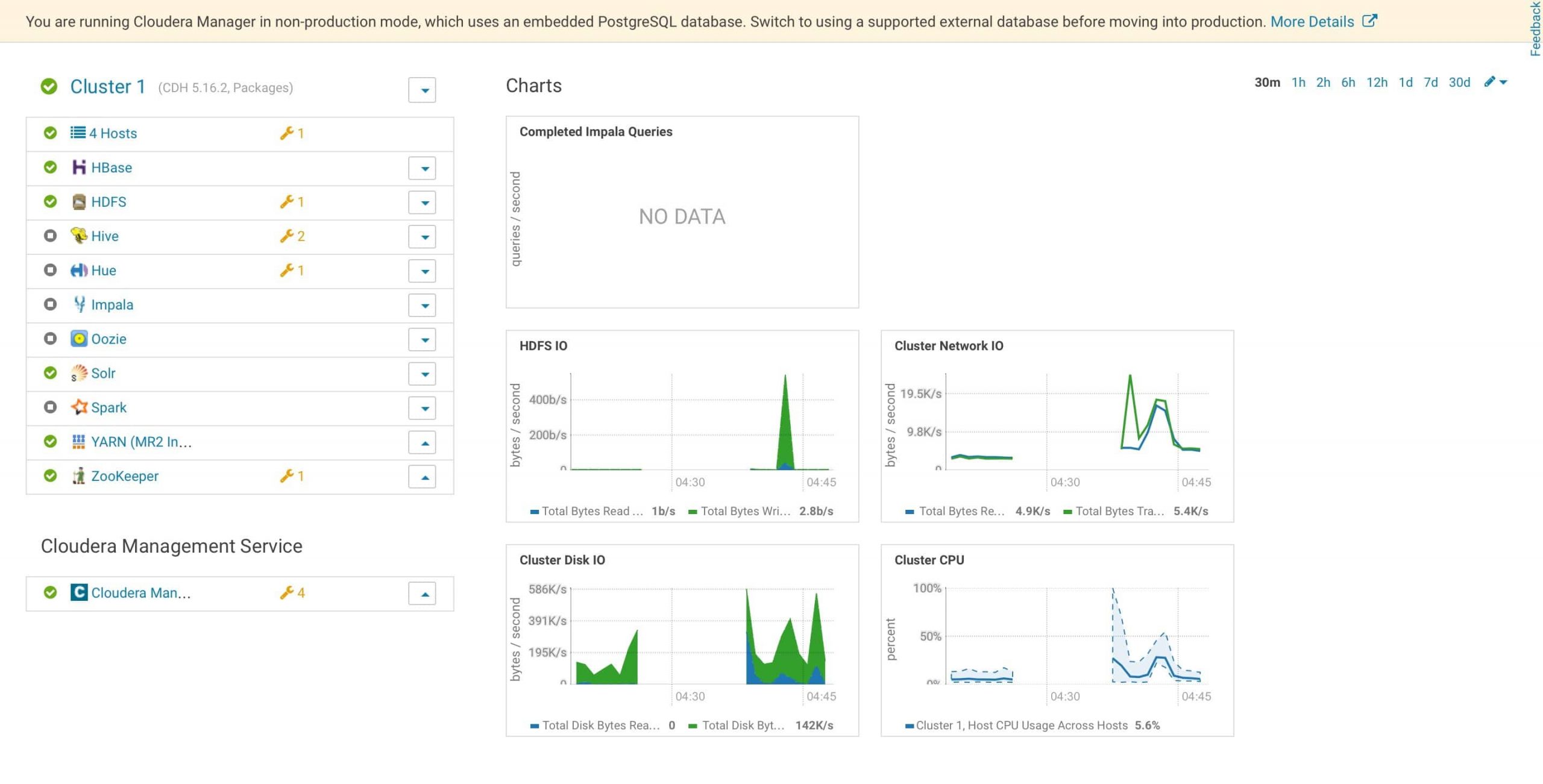
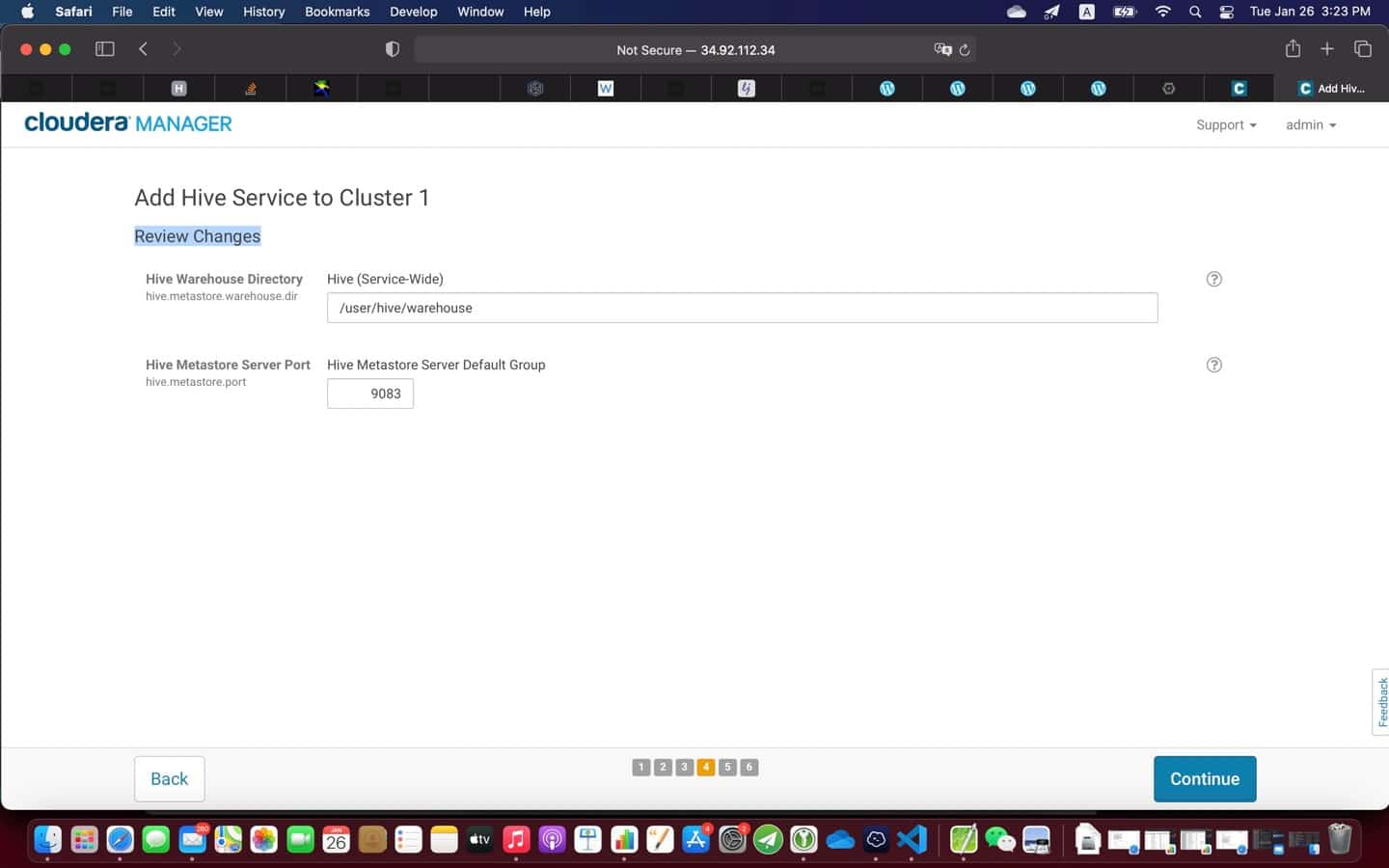
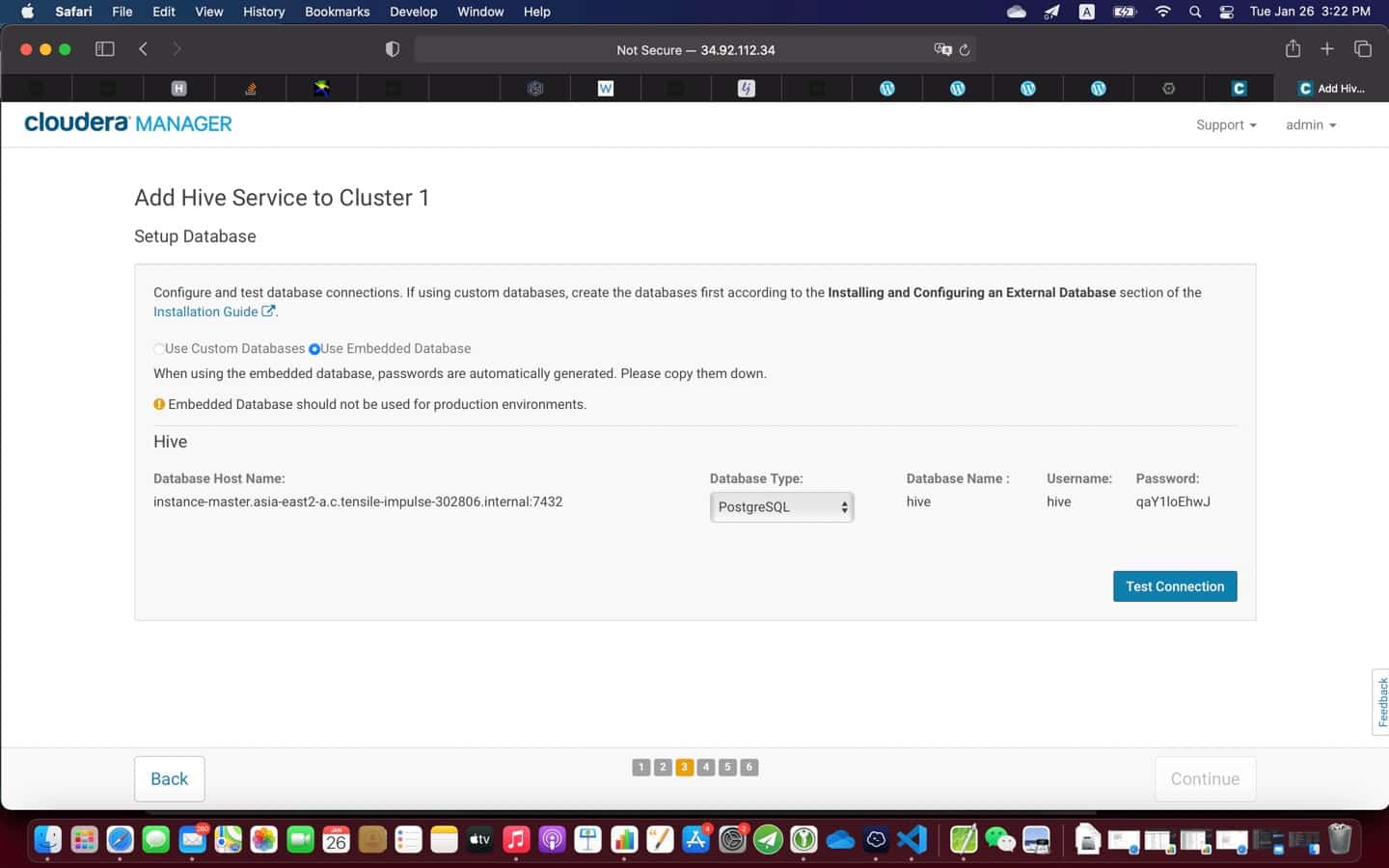
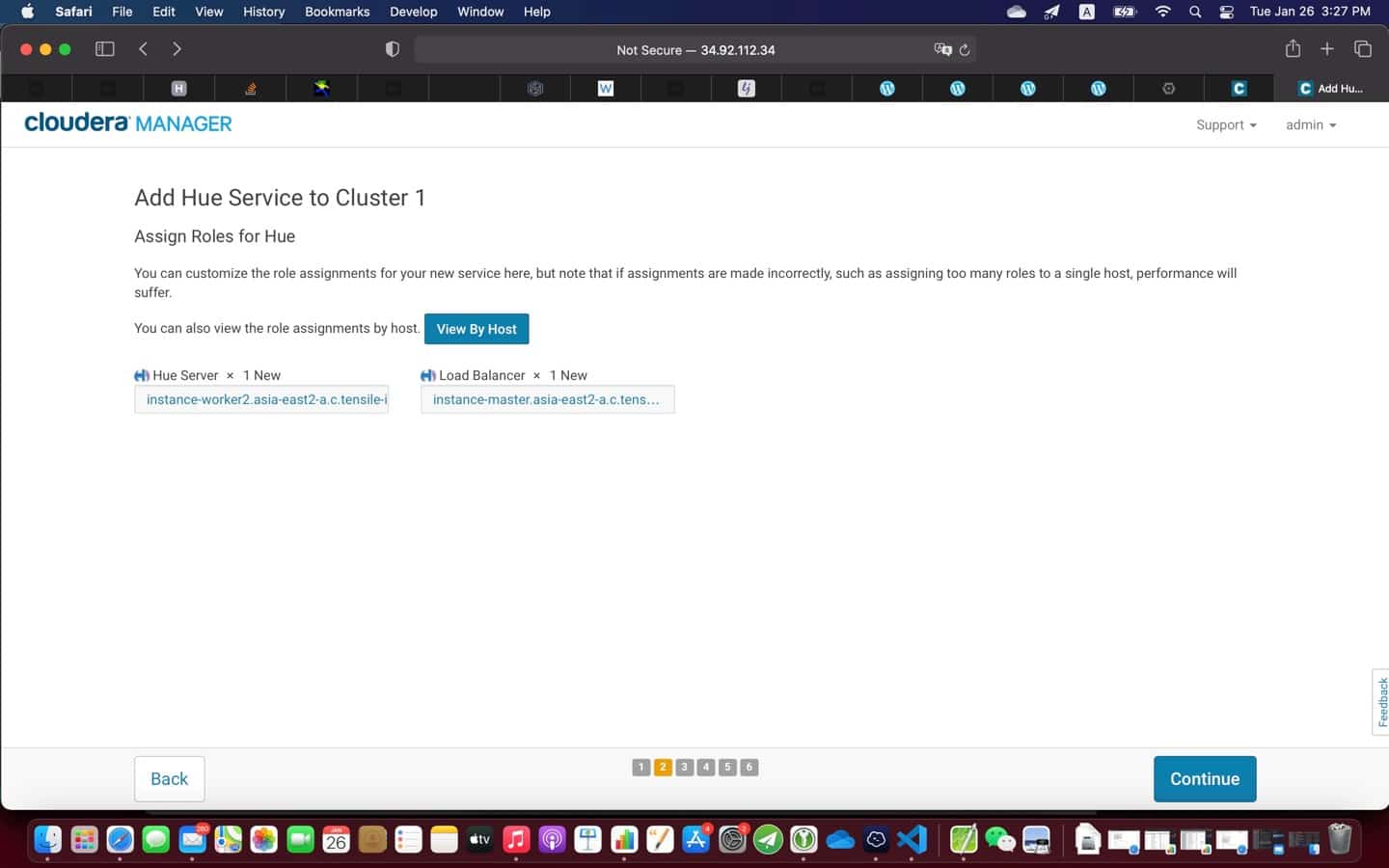
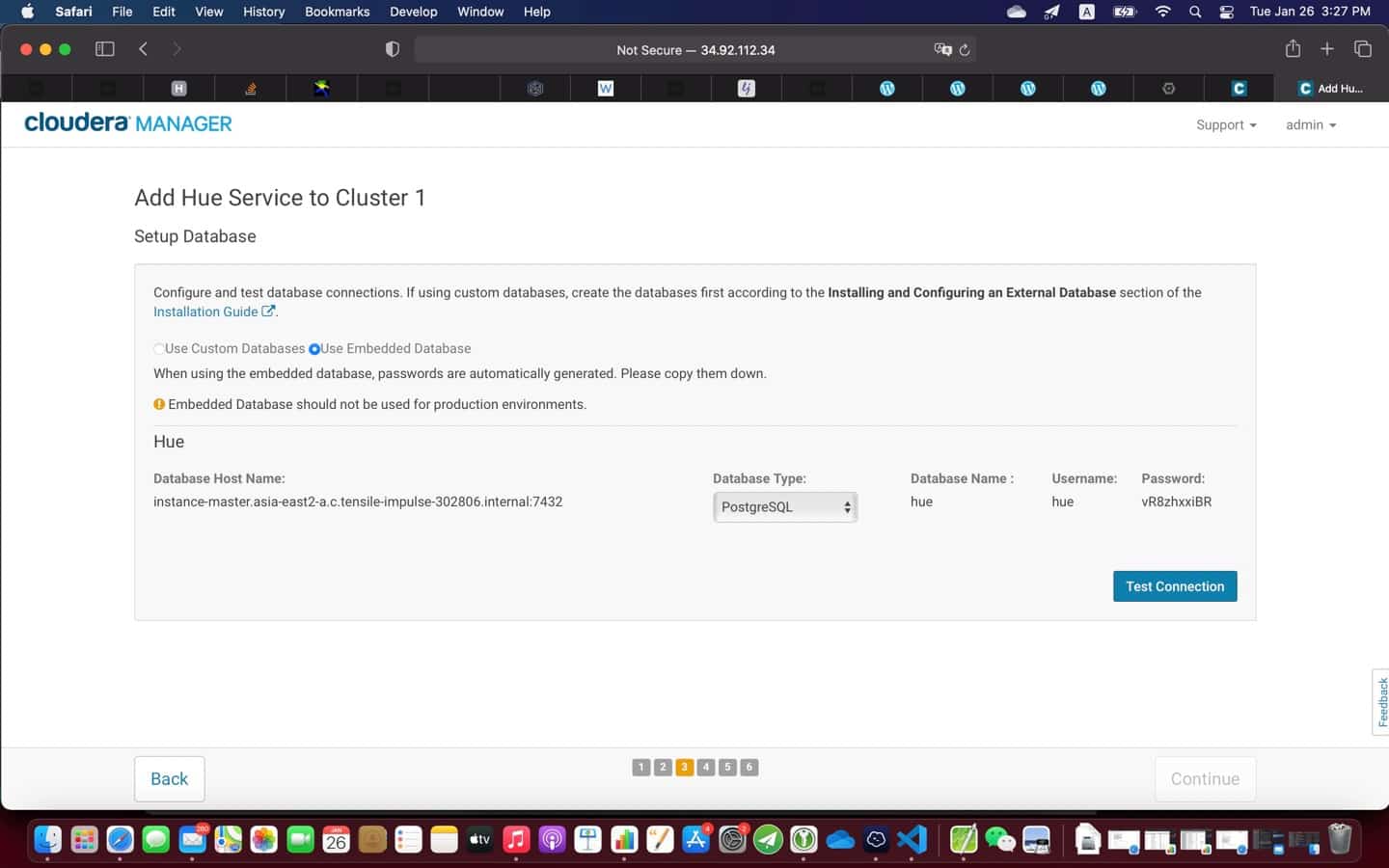
9. Post installation
At the end of the installation (see screenshot above), it is a good practice to test everything is working as expected
- Run JPS to check the Hadoop daemons like NameNode, DataNode, ResourceManager, NodeManager etc. They should be running on the machine
Check YARN and HADOOP UI
http://yourclusterip:8088/cluster
http://yourclusterip:9870/Check Hive Web UI
http://yourclusterip:10002/Hue Web UI
http://yourclusterip:8888/Check Hbase,Hive, hadoop version
hbase version
Hive --version
hadoop version
pig --version
oozie versionCheck Spark
spark-shell
spark-submit --version
Leave a Reply